


Your 30-day trial comes with
Full access to Studio Enterprise
Web, Mobile, Desktop, API testing
Easy setup, 1-click integrations
No credit card required

In Web UI automated testing, a primary concern for testers is high maintenance costs of test scripts, which are usually caused by unstable and broken locators. A locator is a mechanism used by Selenium to identify an element during test execution. The popular locator mechanism is XPath. Unfortunately, locators are easily broken or unable to identify the target element when the application under test (AUT) changes. An existing study showed that locators account for more than 70% of breakages in Web UI test scripts.
Hence creating and using correct and resilient locators are crucial to the success of Web UI test automation.
In this article, we describe a brand-new and intelligent method introduced in Katalon Studio to automatically generate robust locators during the test recording phase. This advanced method produces new locators that are more maintainable and less vulnerable to changes in AUT than do Selenium and other test automation tools.
Let’s look at ted.com, a website built using the EmberJS framework. The screenshot below shows the website’s cards with each contain different items (text, image, link, etc.).
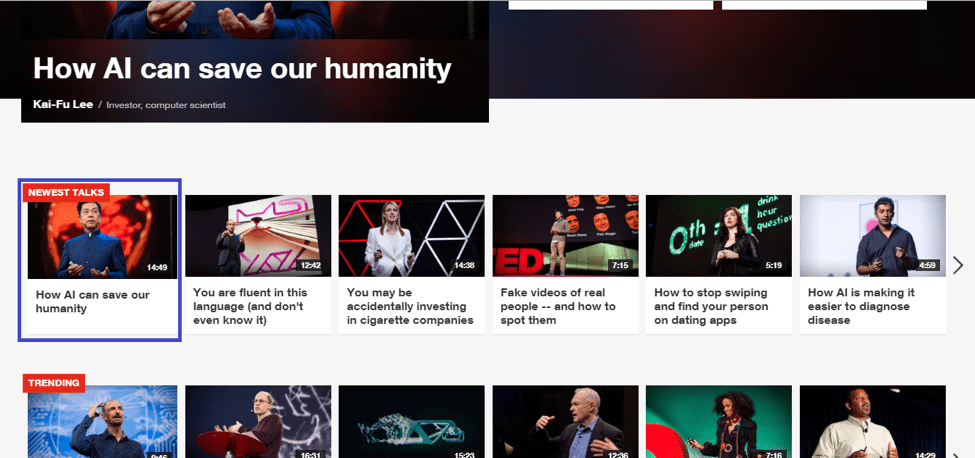
Suppose you want to record a simple action of clicking on a thumbnail of a video, the one with “How AI Can save our humanity”, for example, you would get the following XPaths generated by Selenium:
Selenium’s XPaths |
| //div[@id=’react-container1′]/div/div/div/div/div/div[2]/div/div[2]/div/div/div/a/div/div[2] |
| //div[2]/div/div[2]/div/div/div/a/div/div[2] |
Although these XPaths can locate the element, they are too long and complex. But the main problem is that they are easily broken as they only work if the content is not changed. TED is a fast-growing website with new contents being produced every day. Therefore, it is no surprise that the first video today may be the third video tomorrow. If you look at these XPaths, or just at the last 3 characters, you will notice that they rely entirely on the assumption that the ordering of the video will not change. Such an assumption contradicts reality, as described. In short, these locators are fragile and hard to read and maintain.
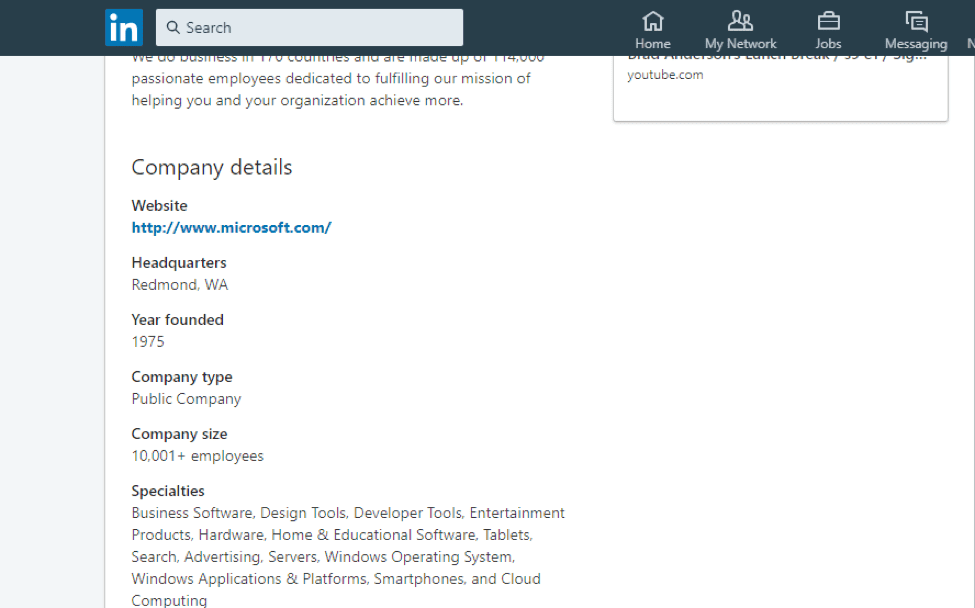
Take another example, Microsoft profile on Linkedin.
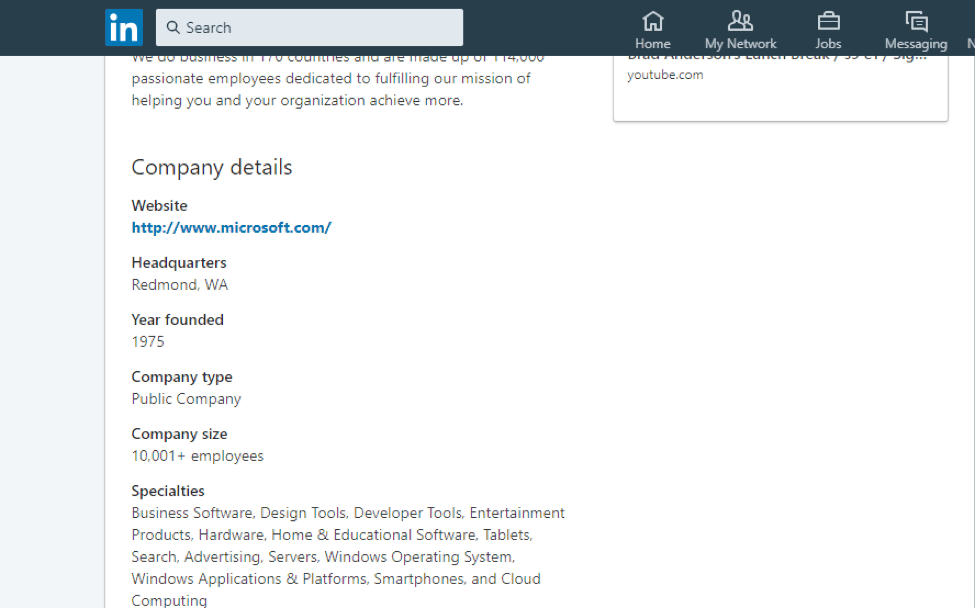
Suppose you want to verify Microsoft’s profile information, and you use Selenium to record by clicking on each of the fields to obtain the XPaths, here’s what you will get:
| Fields | Selenium’s XPaths |
| Website | id=ember1801 |
| Headquarters | //div[@id=’org-about-company-module’]/div/div[2]/div/p |
| Year founded | //div[@id=’org-about-company-module’]/div/div[2]/div/p[2] |
| Company Type | //div[@id=’org-about-company-module’]/div/div[2]/div/p[3] |
| Company Size | //div[@id=’org-about-company-module’]/div/div[2]/div/p[4] |
| Specialties | //div[@id=’org-about-company-module’]/div/div[2]/div/p[5] |
Let’s examine the table above row by row. The website field is located by its ID, which seems to be a reasonable choice. You now can say that at least your test case will successfully locate this field. However, you will later find out that it won’t because the ID is different every time you visit this page. In other words, this ID is dynamic. So using ID as a locator is not a good choice in this situation.
The headquarters field is located by a relatively concise XPath. Unfortunately, this locator identifies five Web elements instead of a unique element as expected. (You can check this by opening Chrome and pressing Ctrl + Shift + I to open the Inspection Tool and search the XPath in the document – shown below).
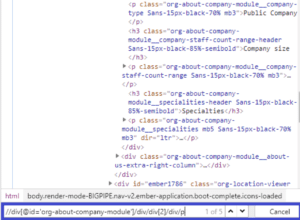
The result is not surprising because indeed there are five Web elements with the tag <p> in the company information section. Some playback engine will automatically select the first element among those five, but some will not.
The remaining XPaths suffer the same problems we already discussed with the TED website.
If an element cannot be consistently located using its direct attributes, then identifying it using its more robust neighbors. That is a simple but powerful idea behind the new locator method introduced in Katalon Studio. This method is visually intuitive as it reflects the way users often identify a visible element on the user interface.
An XPath (also called neighbor XPath) generated by the method follows the following form:
| 1 | 2 | 3 | 4 | 5 |
xpath=(.//*[normalize-space(text()) and normalize-space(.)=’neighbor_text‘]) |
[n]/ | preceding:: |
tag_name |
[m] |
| following:: |
This form assumes that a neighbor of the target element is robust and is identified by its text. Each column in this form is explained as follows:
| Column No. | Discrete description |
| 1 | Retrieve the element using the text of its neighbor |
| 2 | Retrieve the neighbor among those retrieved in step 1 using the neighbor’s index. |
| 3 | From the neighbor, going forward or backward |
| 4 | Retrieve all elements with the same tag name as the target element, then |
| 5 | Retrieve the target element |
Let’s get back to the example with TED:
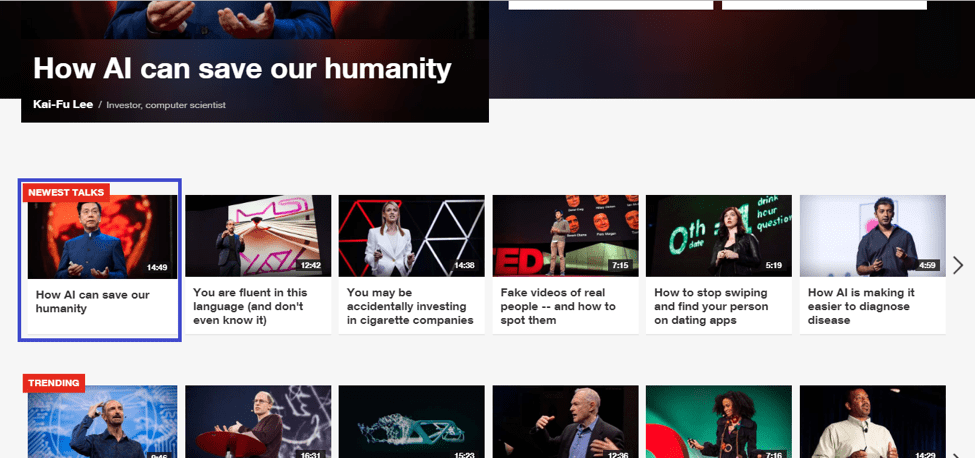
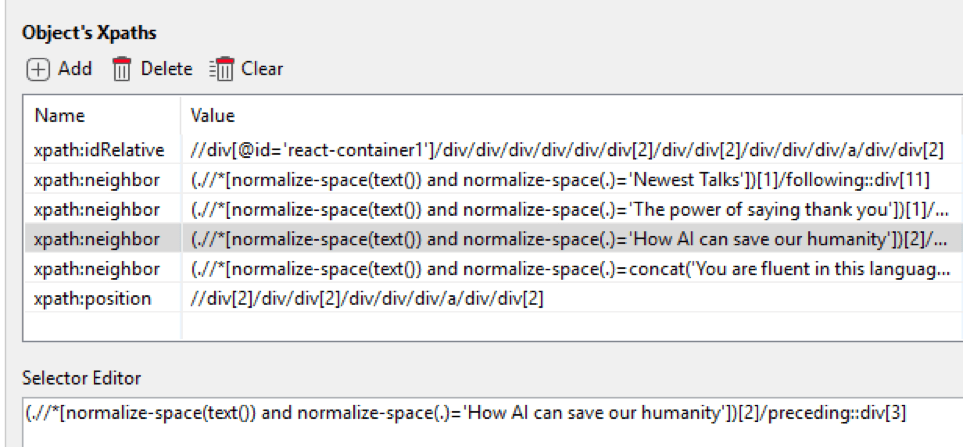
Here are a few XPaths that take on the above form to identify the thumbnail preceding “How AI can save our humanity”.
| Neighbor XPath |
| xpath=(.//*[normalize-space(text()) and normalize-space(.)=’How AI can save our humanity’])[2]/preceding::div[3] |
| xpath=(.//*[normalize-space(text()) and normalize-space(.)=’Newest Talks’])[1]/following::div[11] |
The “xpath=(.//*[normalize-space(text()) and normalize-space(.)” part is fixed, so we can ignore it when maintaining. We instead focus on the rest, which refers to the labels shown in the UI and so it is readable.
The first XPath is the most intuitive because it aligns with how users process and interact with the thumbnail – the label representing the thumbnail. This locator is easy to maintain as when the label on the UI changes, you just have to update the corresponding text in the script. Moreover, the overall template of a video is often more stable than the content (for example YouTube hasn’t changed it templates for years). Therefore the relationship between the target element and its neighbor within a composite item or a card is preserved despite the dynamic orderings between items.
For the Microsoft profile example:
Here are the corresponding neighbor XPaths:
| Fields | Neighbor XPaths |
| Website | xpath=(.//*[normalize-space(text()) and normalize-space(.)=’Website’])[1]/following::a[1] |
| Headquarters | xpath=(.//*[normalize-space(text()) and normalize-space(.)=’Headquarters’])[1]/following::p[1] |
| Year founded | xpath=(.//*[normalize-space(text()) and normalize-space(.)=’Year founded’])[1]/following::p[1] |
| Company Type | xpath=(.//*[normalize-space(text()) and normalize-space(.)=’Company type’])[1]/following::p[1] |
| Company Size | xpath=(.//*[normalize-space(text()) and normalize-space(.)=’Company size’])[1]/following::p[1] |
| Specialties | xpath=(.//*[normalize-space(text()) and normalize-space(.)=’Specialties’])[1]/following::p[1] |
Again, ignoring the fixed part of the XPaths above, we can see that the fields of Microsoft’s profile are embedded in the XPaths. During test execution, if a field is missing then the execution is stopped to indicate exactly what is wrong. With Selenium, however, the incorrect failure item is shown as the order is changed due to an item being removed.
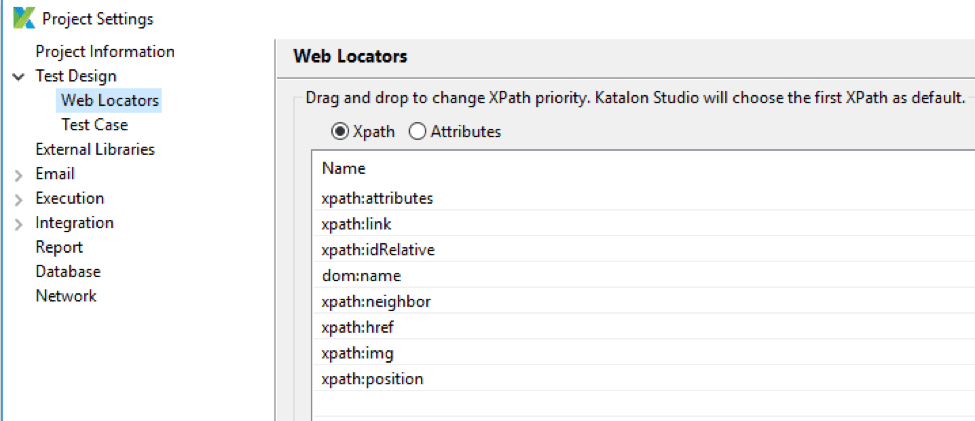
Of course, you do not have to worry much about how to create neighbor XPaths like above. Katalon Studio automatically does the job. Neighbor XPaths are generated during recording. Katalon Studio tries to choose appropriate XPaths, while you can still manually select the most relevant ones as shown below.
With the custom locators strategy setting, you can choose the default strategy for smart XPaths for all test elements.
We showed several examples demonstrating that Selenium’s XPaths are fragile and hard to maintain. The common cause is Selenium’s reliance on an element’s index and ordering.
This article described Katalon Studio’s advanced and intelligent method to automatically generate locators or neighbor XPaths in automation test scripts. The XPaths are more resilient to changes in the AUT and more maintainable than those generated by Selenium. This advanced method is available in version 5.7 of Katalon Studio.

Read more: